
Imagine you are in a huge library with millions and millions of books, and you need to answer a question. What would you do? You could spend hours or maybe days flipping the pages of the books in the Library. What if there is a super smart magical librarian who can find the best books, reads the relevant pages and gives you a clear, accurate answer? That's what Retrieval Augmented Generation is in the world of AI (Artificial intelligence). It's the clever way to make AI smarter by combining the power of searching with story telling.In this blog, we’ll see what RAG is, how it works, and why it is valuable for users across industries, from education to business.
What is RAG?
In the evolving world of Artificial Intelligence, Large Language Models(LLM) like GPT, Claude and Llama have revolutionized how machines understand and generate human-like texts. But the knowledge of these traditional LLMs are static, meaning these are tied to the data they were trained on and can quickly become outdated. RAG was introduced as a solution for this - enabling models to access live, domain specific and verifiable data sources to deliver trustworthy as well as accurate outputs.
The term was first introduced by researchers at Facebook AI (now Meta AI) in 2020 as a method to boost LLM reliability. RAG connects an LLM to an external database, document store, or knowledge graph to “retrieve” relevant information before producing a response.
Unlike classic LLMs that rely solely on their training data, RAG models dynamically pull the latest facts or context during runtime, integrate that information into the prompt, and then generate informed answers. This dramatically reduces the chance of producing hallucinated or outdated responses
How it works
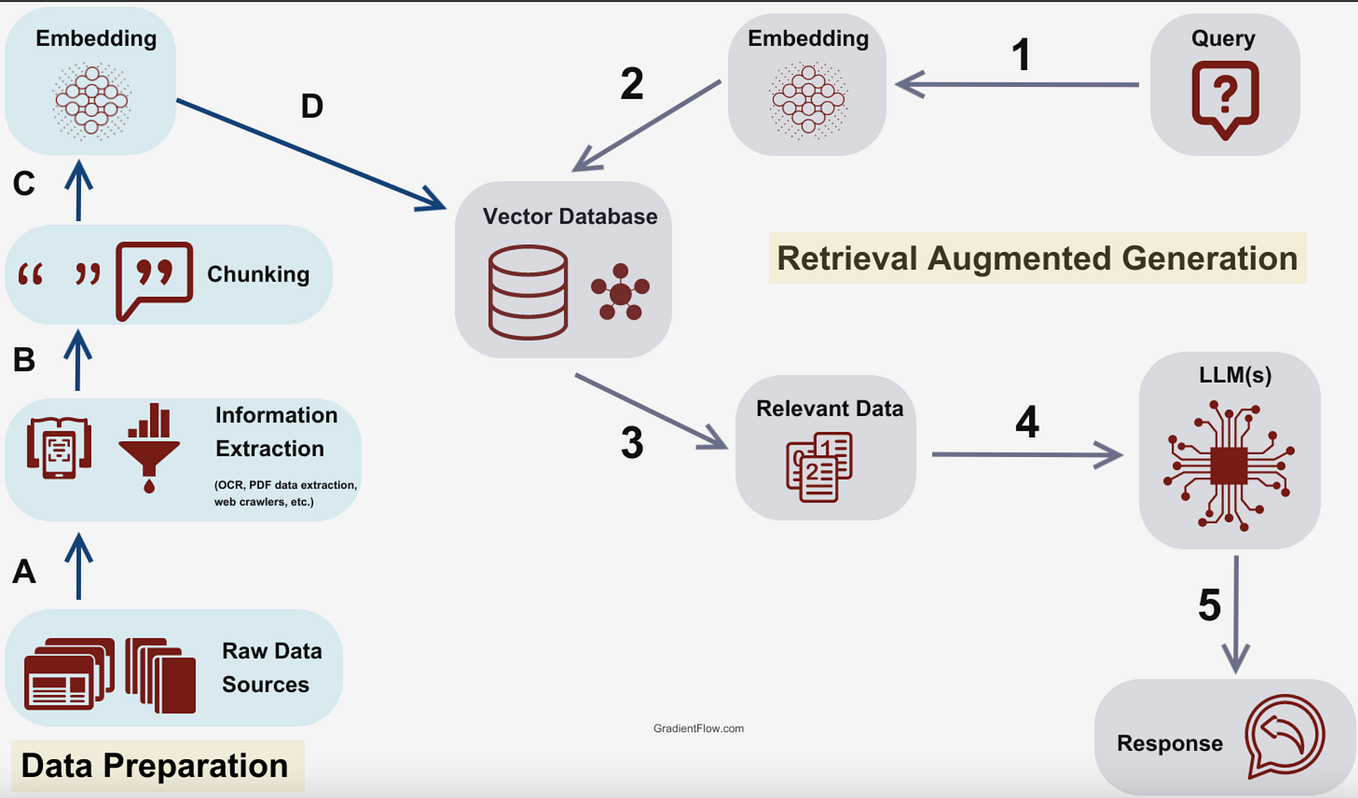
The Architecture and workflow
Key components in the Architecture :
- Embedding model - Converts text into numerical vectors so that meaning can be compared.
- Vector database - Stores vectors for all documents and enables quick similarity searches.
- Retriever - Searches for the most relevant documents related to a query.
- Augmenter - Combines query text with retrieved information to create a useful prompt.
- Generator (LLM) - Produces the final response based on the augmented prompt and its learned language abilities.
- Knowledge Sources - External data such as PDFs, APIs, or databases that feed the system with real knowledge.
Step by Step workflow :
A RAG system usually goes through this workflow. :
- Query Encoding – The user’s question is turned into a mathematical form called a “vector” by an embedding model.
- Document Encoding – Documents in the database are also converted into vectors beforehand.
- Vector Search – The system compares the query’s vector to document vectors to find similar or related ones. This is done using similarity measures such as cosine similarity.
- Context Retrieval – The closest matching text chunks are retrieved from a vector database (like FAISS, Milvus, or Chroma).
- Prompt Augmentation – The retrieved text is added to the user’s question to create a more complete, detailed prompt.
- Generation – The prompt and retrieved data are sent to the LLM, which creates a grounded and coherent answer using both its stored knowledge and the updated data.
- Response Output – The final answer is displayed to the user, often backed by references to the sources used.
Example Use
Suppose a bank uses a RAG-powered chatbot. When a customer asks, “What’s my credit card limit?”, the system works like this:
The retriever looks in the internal database and the user’s account details.
The generator combines that found data with the question to create a customized, accurate reply — such as “Your credit card limit is ₹1,50,000 as per your Platinum account.”
The architecture of RAG combines searching and generating into one single process. The retriever ensures the AI has the information and facts , and the generator ensures the answer is clear and natural. By linking LLMs with real-time information, RAG systems produce responses that are more current, relevant, and reliable — which is why they are becoming the standard design for modern AI assistants and enterprise chat systems
